Side by side speed comparison
Autoregressive decoding, DFlash, and DDTree run on the same prompt, with the lower DDTree verification panel showing the draft tree and accepted path.
One DDTree decoding round
A single round starts from the previous bonus token, builds a draft tree, verifies it with one forward pass, and carries the next bonus token forward.
The block diffusion draft model runs one forward pass and outputs per-position distributions for the next block.
Speedups relative to autoregressive decoding
Speedups across datasets, per model and temperature.
How DDTree works
Vanilla DFlash already delivers strong acceptance lengths and speedups while keeping drafting cheap by predicting a block in one diffusion pass, but it still verifies only one drafted trajectory per round, so most of that output is never used. DDTree instead uses the drafter's per-position predictions to build a tree of likely continuations rather than collapsing them into a single path.
At each round, DDTree builds a draft tree under a fixed node budget, choosing the branches that look most promising. The target model then verifies the whole tree in one forward pass with tree attention.
The procedure remains lossless: the target model uses its own decoding rule, so DDTree preserves exactly the target model's output distribution. The verifier walks as long as the chosen token matches a child in the tree and commits the matched prefix. When the walk leaves the tree, DDTree stops and carries the first unmatched target token into the next round as the new bonus token.
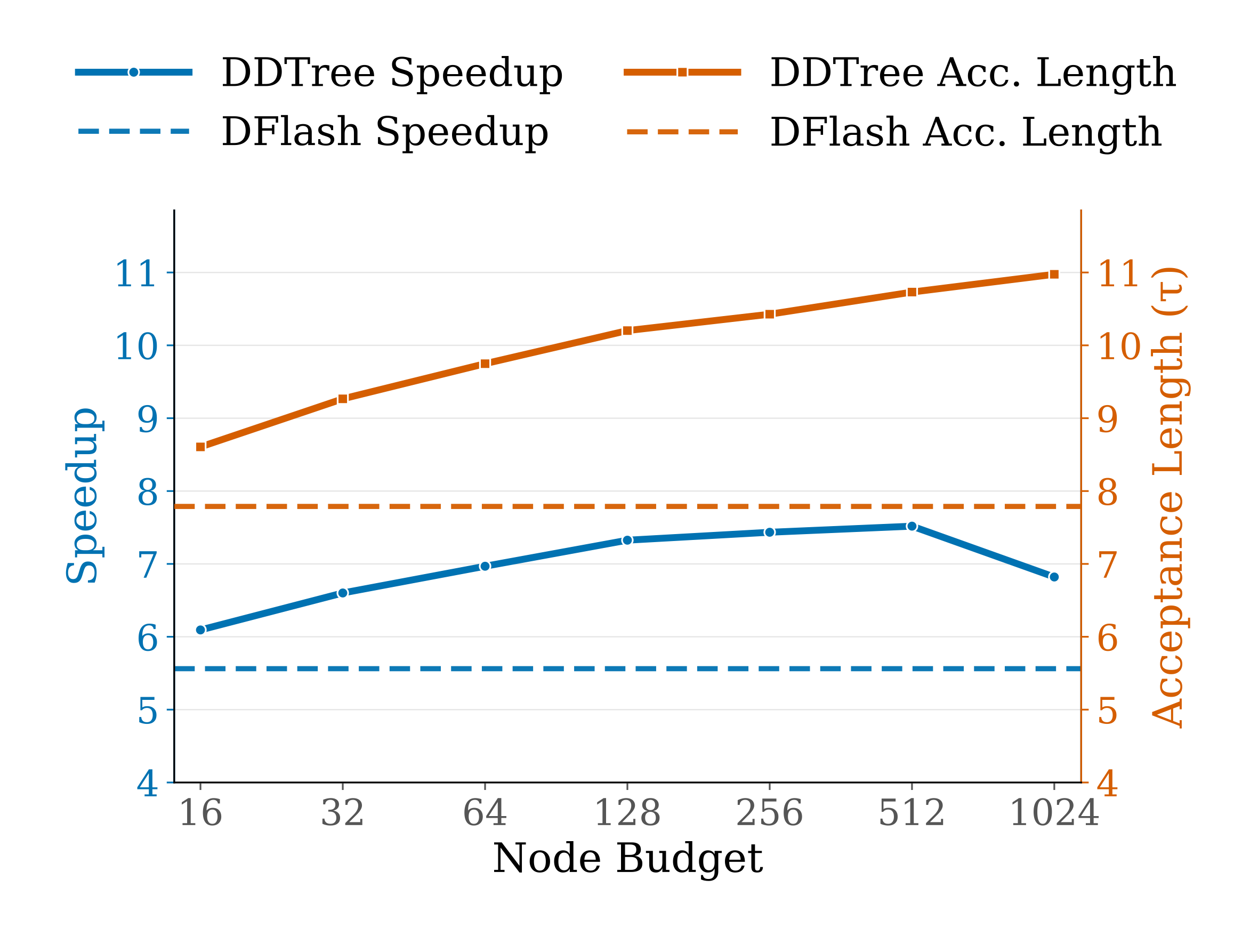
On MATH-500, acceptance length rises steadily as the DDTree node budget grows, but speedup peaks at an intermediate budget once verifier cost becomes dominant.
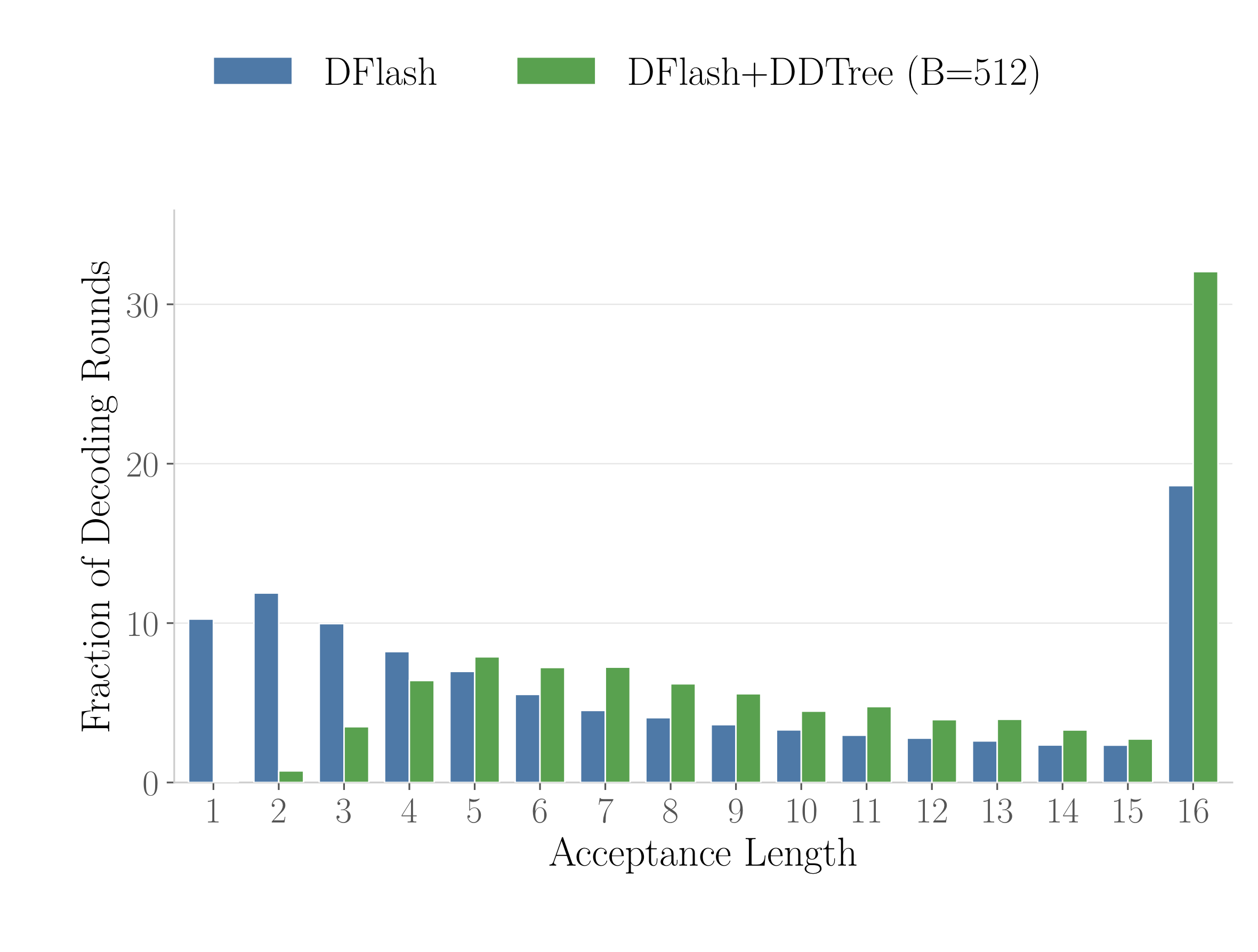
On MATH-500, DDTree shifts mass toward longer accepted prefixes, making short acceptances rarer and full-block acceptances substantially more common.
Citation
@article{ringel2026ddtree,
title={Accelerating Speculative Decoding with Block Diffusion Draft Trees},
author={Ringel, Liran and Romano, Yaniv},
journal={arXiv preprint arXiv:2604.12989},
year={2026}
}